
Petite pause dans les dossiers classiques que je rédige pour revenir à mes premiers amours autour du traitement de données spatialisées !
Ce « petit » dossier me permet de partager et valoriser le travail réalisé avec un château viticole pendant plusieurs millésimes d’affilé. Ce château viticole a certes le temps et les moyens pour collecter de la donnée à haute résolution mais aussi la motivation pour comprendre et engager un travail de réflexion autour de cette donnée.
Dans ce travail, je vous propose ainsi une méthodologie pour synthétiser l’information contenue dans des historiques (7 ans et plus) de cartographies intra-parcellaires de végétation sur des parcellaires étendus. Je vous apporte ici quelques éléments méthodologiques et théoriques certes, mais j’essaierai de vous montrer que dans des contextes opérationnels, il faut accepter de faire un certain nombre de deuils, que ce soit en termes de qualité de données récoltées ou de chaine de traitement de l’information. Je ne suis bien évidemment pas en train de dire que l’on peut accepter de travailler comme des cochons – il faut tendre vers le mieux – mais il est nécessaire de s’adapter aux conditions du terrain. La réalité est souvent moins rose que la théorie. Bref, revenons-en à notre méthodologie. L’approche présentée ici consiste à fournir deux indicateurs différents :
- un indicateur d’hétérogénéité spatiale de végétation, ou en d’autres termes : « est ce que la parcelle est homogène ou hétérogène ? », et
- un indicateur d’instabilité temporelle de végétation, c’est-à-dire : « est-ce que les structures de végétation à l’intérieur des parcelles sont stables ou pas dans le temps ? »
Ces indicateurs, utilisés en relatif, permettent en autre de hiérarchiser les parcelles en termes de variabilité spatiale au cours du temps pour aller par exemple prioriser des interventions modulées sur certaines parcelles plutôt que d’autres ou pour (ré)-organiser l’allotement des parcelles du domaine. Ces indicateurs sont aussi un moyen d’évaluer l’intérêt de comparer des variations de végétation avec des itinéraires culturaux mis en place dans les parcelles. Comprenez-ici que si les structures et patrons spatiaux de végétation évoluent beaucoup dans le temps, il y a quand même beaucoup de chances que ce soit dû à des itinéraires choisis sur les parcelles concernées.
La méthodologie, utilisée ici dans le contexte de données de végétation en viticulture, est redéployable dans d’autres filières et pour d’autres typologies de données agronomiques où de longs historiques sont disponibles.
La bibliographie est courte et assez auto-centrée, ne vous en déplaise… mais vous pourrez y retrouver dedans de nombreuses autres références qui, je l’espère, pourront vous être utiles. L’objet de ce dossier est essentiellement de partager un retour d’expérience opérationnel.
Soutenez Agriculture et numérique – Blog Aspexit sur Tipeee
Pourquoi avoir fait ce travail ?
Exploiter des données à haute résolution acquises ponctuellement sur une parcelle à une date donnée n’est déjà pas évident. Néanmoins, cette donnée reste accessible pour un œil humain si l’on fait l’effort de la présenter au moins sous une forme cartographique. Cette donnée peut être difficile à comprendre si elle n’est pas transformée en information agronomique mais le nombre de dimensions autour de cette donnée (une année, une parcelle, une variable) reste relativement faible.
Lorsque l’on commence à augmenter le nombre de parcelles étudiées, et ce sur plusieurs années, il devient alors très difficile de s’abstraire de cette complexité, de dégager des tendances, et de prendre du recul sur ce qui se passe réellement sur l’exploitation. Les dimensions autour de ces données sont trop importantes pour que notre cerveau soit capable de les synthétiser tout seul et nous pouvons alors être biaisés dans leur interprétation.
Et les sources de biais sont terriblement nombreuses… Couleurs de l’affichage des données, taille et forme des parcelles, nombre d’années d’analyse, expérience personnelle du terrain ; j’en passe et des meilleures. Ces biais sont déjà présents lorsque l’on regarde une cartographie intra-parcellaire. Alors quand on regarde des historiques de cartes sur de grands parcellaires, je vous laisse imaginer la suite. Petite digression rapide autour du biais de couleur des cartes. Je serais tenté de demander à plusieurs opérateurs différents de découper des zones de végétation sur des parcellaires en utilisant des cartes avec des gradients de couleurs différents. Exactement le même processus de traitement de données mais juste avec les couleurs du gradient qui changent (du vert au rouge et du bleu au vert par exemple). Bien que j’attende des différences entre opérateurs, je suis persuadé aussi qu’un même opérateur serait capable de découper la même parcelle différemment si les gradients de couleurs sont changeants.
Le déploiement des outils numériques depuis maintenant plusieurs années favorise l’acquisition de données multi-dimensionnelles (plusieurs variables, plusieurs parcelles, plusieurs années) – des passages récurrents plusieurs fois dans la saison et/ou sur plusieurs saisons pour suivre l’évolution de paramètres agro-pédo-climatiques. Dans la communauté de l’agriculture de précision, plusieurs auteurs ont déjà tenté de synthétiser ces informations complexes mais souvent sur l’une ou l’autre de ces dimensions. On peut penser par exemple à certains travaux autour d’indices d’opportunité de modulation (Leroux and Tisseyre, 2018a) pour tenter de décrire, en un indicateur, si une parcelle présente une amplitude de variation et une structure spatiale suffisantes pour qu’il soit pertinent d’y imaginer une application modulée. On reste ici sur un enjeu spatial et ces indicateurs ne sont pas nécessairement comparables d’une parcelle à l’autre. Côté synthèse d’information temporelle, la première chose qui me vient à l’esprit est peut-être les premiers travaux autour d’historiques de cartes de rendement (ceux de Simon Blackmore par exemple) pour identifier, au sein d’une même parcelle, des zones de rendement stables et instables dans le temps. On reste ici sur un enjeu temporel où l’on travaille généralement au sein d’une seule parcelle et que l’on ne cherche pas à comparer des parcelles entre elles.
En s’inspirant de tous ces travaux, nous avons cherché ici à travailler à la fois dans le domaine spatial mais aussi dans le domaine temporel pour comparer des parcelles sur lesquelles nous disposions d’historiques de cartes de végétation.
Matériel et méthodes
Sites et jeux de données
Nous avons travaillé sur 2 sites viticoles différents dans le Bordelais :
Site 1 : Environ 150 parcelles, un peu plus d’une centaine d’hectares, 2 cépages majoritaires (Sémillon, Sauvignon Blanc),
Site 2 : Un peu plus de 200 parcelles, près de 250 hectares, 3 cépages majoritaires (Cabernet Sauvignon, Merlot, Petit Verdot),
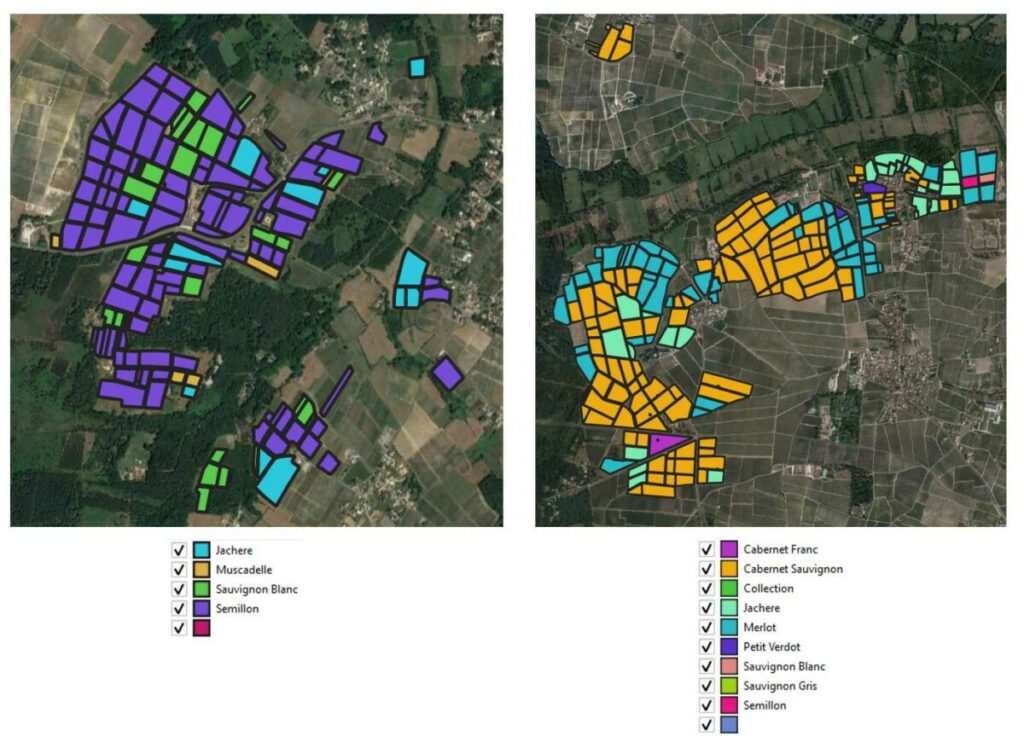
Figure 1. Les sites de travail (1 à gauche, et 2 à droite)
Sur ces 2 sites, l’équipe du domaine avait à disposition un certain nombre de cartes historiques de végétation – sur 7 ans pour le site 1, et sur 8 ans pour le site 2. Pas mal déjà me direz-vous, ça commence à faire un joli recul ! Bon, et bien, feu vert alors ! On calcule ces indicateurs d’hétérogénéité et terminé bonsoir ? Minute papillon… Laissez-moi quand même revenir sur le fait que ces données ne sont pas complètement homogènes. Gloups ! Le contexte opérationnel du travail fait partie des raisons pour lesquelles les données de végétation sont différentes d’une année à l’autre. Les fournisseurs de cartes de végétation ont changé au cours du temps (donc la même méthodologie d’acquisition et de pré-traitement de la donnée a changé elle-aussi), les capteurs et technologies ont aussi pu évoluer dans le temps, la réflexion du château viticole a forcément muri également. Les tableaux 1 et 2 vous donnent quelques premiers éléments de lecture sur les données à disposition et sur l’harmonisation des données que nous avons entreprise.
Tableau 1. Caractéristiques des données de végétation à disposition pour le site 1. Les données sont globalement acquises sur la même période chaque année (juillet)
| Année | Donnée à disposition | Fournisseur | Process d’harmonisation et/ou commentaire |
| 2011 | NDVI (4 GreenSeeker sur l’enjambeur) – pas de réflecteur blanc | A | Données individualisées sur le rang pour chacun des 4 capteurs à disposition |
| 2012 à 2016 | NDVI (3 GreenSeekers sur l’enjambeur) –avec réflecteur blanc | A | Les données des 3 capteurs sont moyennées directement pendant l’acquisition (il n’y a pas de données individuelle de chaque capteur récupérable). Les valeurs très faibles de végétation (pieds manquants ou autre) sont donc directement moyennées et non séparables du reste des données (si l’on avait eu envie de les séparer par exemple). Bugs des capteurs et changements des capteurs pendant la période |
| 2017 à 2019 | NDVI (3 GreenSeekers sur l’enjambeur) –avec réflecteur blanc | A | Donnée individualisée pour chacun des 3 capteurs à disposition |
| 2020 | EVI sur le rang (vol avion) | C | Non utilisé dans ce travail |
Tableau 2. Caractéristiques des données de végétation à disposition pour le site 2. Les données sont globalement acquises sur la même période chaque année (juillet)
| Année | Donnée à disposition | Fournisseur | Process d’harmonisation et/ou commentaire |
| 2016 | Réflectance sans distinction de l’inter-rang (vol avion) | B | Pas de données NDVI. Informations sur 4 bandes avec valeurs de réflectance (0 à 255). Format Raster. Ce ne sont pas les données brutes, les données avaient déjà été lissées |
| 2017 | NDVI sur le rang (vol avion) | B | |
| 2018 | NDVI sur le rang (vol avion) | B | Donnée pré-classifié de NDVI, ce ne sont pas des données brutes (qui ne sont plus accessibles). Les données sont sous forme de maille régulière (ce ne sont pas des données ponctuelles comme le reste des données). Il semblerait qu’un raster ait été classifié puis vectorisé brutalement sans pré/post-traitement |
| 2019 | NDVI sur le rang (vol avion) | B | |
| 2020 | EVI sur le rang (vol avion) | C | |
| 2021 | EVI sur le rang (vol avion) | C | Traitement long du fournisseur à cause d’une année très pluvieuse qui rendait très visible l’enherbement |
| 2022 | EVI sur le rang (vol avion) | C | 2 passages, un pendant l’été et un juste avant la récolte (seul le passage pendant l’été a été utilisé) |
Nous avons tenté d’harmoniser les données au mieux de manière à obtenir des données ponctuelles de végétation sur l’ensemble des parcellaires, avec des tables d’attributs cohérentes. Nous avons accepté que les indicateurs de végétation ne soient pas les mêmes d’une année à l’autre, et nous avons fait en sorte, par la suite, de travailler en maximum en relatif d’une année à l’autre pour justement pallier ces effets (nous en rediscutons plus bas).
Et puisque l’objectif est de vous faire des retours d’expérience, je me permets également de vous partager quelques joyeusetés vécues pendant le travail. Joyeusetés pour lesquelles vous aurez besoin d’un punching-ball, d’une salle insonorisée, d’exercices de méditation avancée, et potentiellement d’appeler maman si vous êtes vraiment au bout de votre vie :
- les données fournies ne sont pas toujours dans le même système de coordonnées de référence (https://www.aspexit.com/les-systemes-de-coordonnees-de-reference/). Et ça c’est quand vous avez de la chance et qu’un système de coordonnées de référence est présent…
- les tables d’attributs des couches ne sont pas tout le temps structurées pareil
- le parcellaire a des défauts de topologie et/ou d’attributs : certaines parcelles se chevauchent, certaines ont des trous dont on ne sait pas trop comment ils sont arrivés là, d’autres encore sont découpées en plusieurs parcelles disjointes mais ont le même identifiant
- certaines données sont manquantes et vous finissez par vous rendre compte que certaines parcelles n’ont pas été traitées parce que les données n’étaient pas présentes dans le fichier initial
- le parcellaire a évolué dans le temps mais vous l’apprenez à vos dépends un peu tard
- les métadonnées des couches ne sont pas renseignées et on ne sait plus vraiment à quelle date les données ont été acquises ou numérisées
- les itinéraires culturaux sur les parcelles, surtout pour les premières années de végétation, ne sont plus toujours bien connus et suivi
- ….
Je force bien évidemment un peu le trait ici tant le temps passé à nettoyer et préparer la donnée est souvent sous-estimé. Je tiens quand même à souligner les gros efforts et la volonté de ces deux domaines viticoles de déjà faire un état de l’art des données à disposition et ensuite de centraliser l’existant de manière à pouvoir exploiter un tel historique de données. Ces premiers travaux servent à essuyer les plâtres et à partager des retours d’expérience dont les suivants pourront largement s’inspirer.
Zonage des cartes de végétation
Les données de végétation harmonisées ont été zonées (découpées), année par année, en utilisant un algorithme de croissance puis de fusion de zones, inspiré du domaine de la segmentation d’images, mais appliqué à des données ponctuelles (Leroux et al., 2017). La figure 2 présente cette approche dans une forme imagée. En termes plus français, disons que c’est comme si vous laissiez des taches d’huile s’étendre sur les parcelles et former au fur et à mesure des zones de plus en plus grandes jusqu’à ce que l’ensemble de la parcelle soit recouverte d’huile. Le nombre initial et la position des taches d’huile étant choisies en fonction de la variabilité observée dans la parcelle.
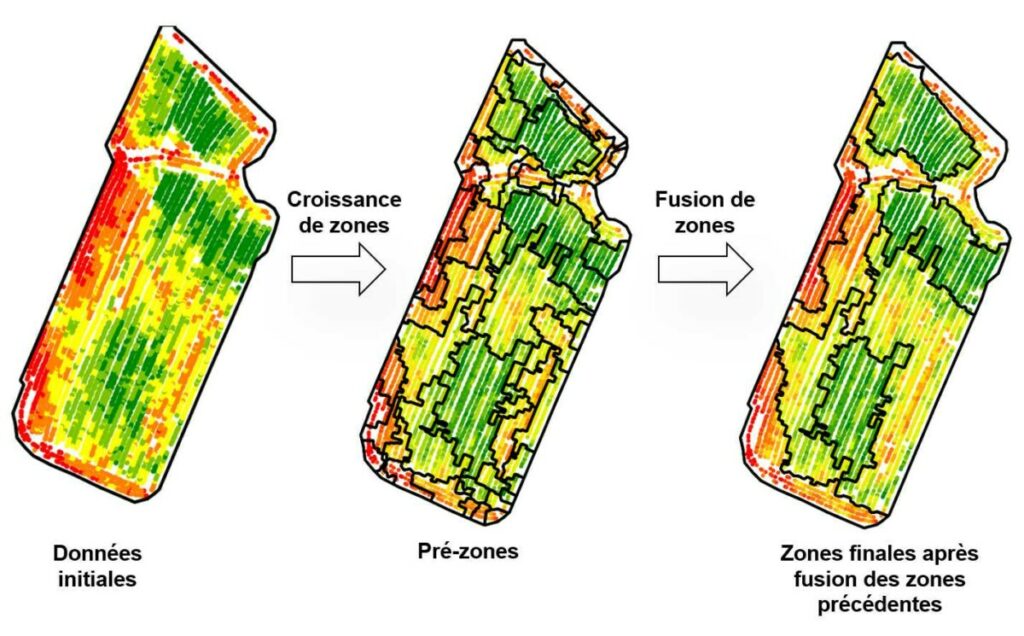
Figure 2. Méthodologie pour zoner (découper) une parcelle automatiquement.
Même si un zonage multi-annuel aurait été possible, c’est-à-dire proposer un zonage agrégatif de plusieurs années d’un seul coup (c’est ce que nous avions proposé pendant ma thèse – Leroux et al., 2018b), il a été décidé ici de réaliser un zonage annuel parce que les sources de données de végétation étaient, au départ, relativement différentes entre années (voir la section « Sites et Jeux de données »). La comparaison des zonages entre années est réalisée dans un deuxième temps (voir section suivante).
Pour chaque année et chaque parcelle, le nombre final de zones (Figure 2) est défini automatiquement par l’algorithme en fonction d’un critère d’arrêt pendant la fusion des zones (Leroux et al., 2017). Le nombre de zones est donc potentiellement différent entre chaque parcelle d’une même année et/ou entre chaque année d’une même parcelle.
Pour simplifier les zonages à l’échelle du parcellaire entier, les valeurs médianes de chaque zone de végétation ont été classées, année par année, tous cépages confondus, en 6 classes différentes en utilisant une classification par intervalles égaux. Les zones de végétation voisines avec la même valeur de classe de végétation ont ainsi été fusionnées, le processus résultant en un zonage plus grossier que celui obtenu à la fin de l’algorithme de zonage automatique (Figure 3).
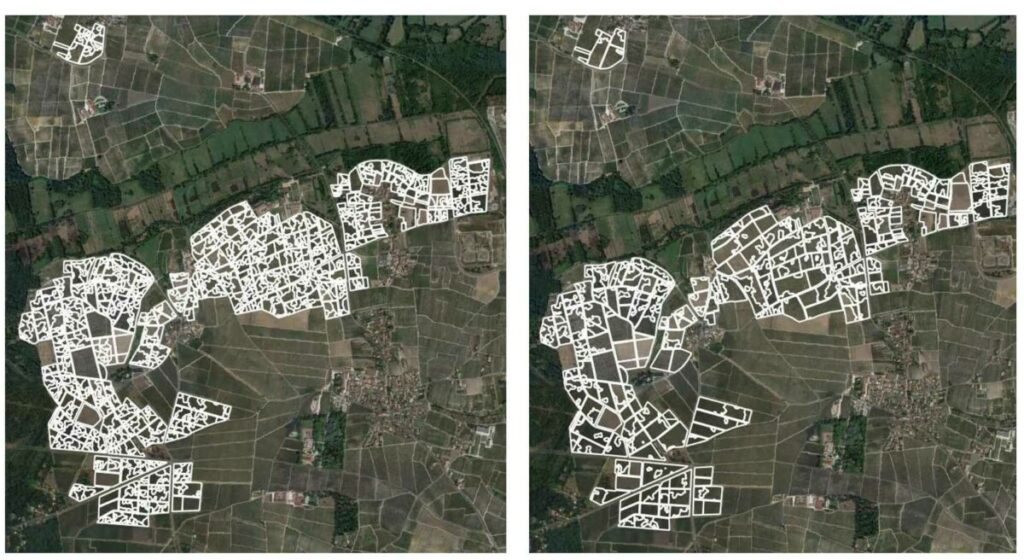
Figure 3. Zonage de végétation sur l’année 2020 pour le site 2. A gauche, après croissance et fusion de zones. A droite, après une classification ultérieure en 6 classes de végétation
C’est ce zonage, construit à partir des données de végétation harmonisées, et de l’algorithme de zonage de Leroux et al., (2017) qui sera utilisé dans la suite de cette étude.
Comparaison des zonages dans le temps
D’un point de vue opérationnel, il est intéressant de distinguer :
- Les parcelles homogènes et les parcelles hétérogènes, de manière à pouvoir hiérarchiser les parcelles qui pourraient être le lieu d’application modulées ou de réorganisation, et
- parmi les parcelles hétérogènes, celles dont les patrons de végétation sont stables dans le temps, c’est-à-dire celles dont pour lesquelles il est envisageable de raisonner sur du long terme et, au contraire, celles dont les patrons de végétations varient dans le temps, c’est-à-dire celles dont la gestion se raisonnera plutôt sur le court terme
Deux indicateurs ont été prévus à cet effet, ils sont détaillés ci-dessous. Le calcul de ces indicateurs est également représenté dans la Figure 4.
Evaluation de l’hétérogénéité des parcelles
Pour chaque parcelle et chaque année, le zonage parcellaire a été utilisé pour calculer un indice de réduction de variance (RV) de zones (voir équation ci-dessous), c’est-à-dire un indicateur de la capacité du zonage à représenter la variabilité spatiale sous-jascente des données de végétation (Bobryk et al., 2016). Cet indicateur varie de 0 à 1. Proche de 0, il vous indique en gros que votre zonage ne sert pas à grand-chose parce que la variabilité dans chacune des zones est globalement la même que si vous n’aviez rien fait. Schématiquement, c’est par exemple le cas si vous aviez une parcelle dont la moitié nord était très vigoureuse, le sud était très chétif, et que l’algorithme de zonage vous proposait un découpage est-ouest. Alors, vous pourrez toujours me dire que c’est l’algorithme de zonage qui est potentiellement mauvais – et vous aurez raison – mais on va partir du principe que l’algorithme ne raconte pas n’importe quoi et qu’une vérification visuelle post-zonage permet de s’assurer que le zonage est cohérent avec les données.
Si l’indice de réduction de variance est proche de 1, là, au contraire, la variabilité dans chaque zone a largement diminué par rapport à la variabilité totale dans la parcelle. Dans la réalité, l’indice n’est jamais vraiment à 1 parce que ça voudrait dire que toutes les données sont exactement identiques dans chaque zone ou que chaque zone ne contient qu’une seule donnée ponctuelle.
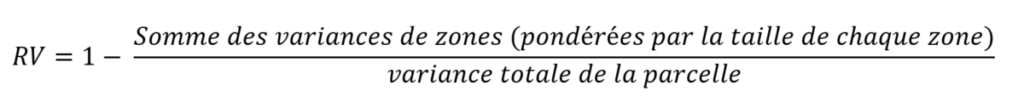
Pour la suite du dossier, je note ici RV_i,j,k l’indice de réduction de variance pour la parcelle i, en utilisant les données de végétation de l’année j, et le zonage de l’année k. Vous serez peut-être surpris de voir que j’utilise deux lettres différentes pour parler des années mais c’est parce que vous allez voir que je propose de plaquer des zonages d’une année j sur les données de végétation d’une année différente k, notamment pour le 2ème indicateur proposé (Figure 4). Patience patience…
Le premier indicateur d’hétérogénéité (l’hétérogénéité pluri-annuelle d’une parcelle, que l’on va noter Het_i), c’est-à-dire celui qui répond à la question : « est ce que la parcelle est homogène ou hétérogène ? », est défini comme la moyenne des indices de réduction de variance sur l’ensemble des années pour la parcelle i, lorsque l’année du zonage et identique à celle des données de végétation :
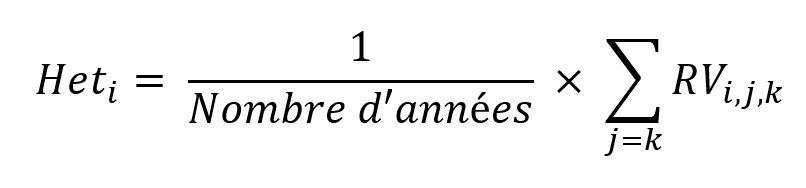
Evaluation de l’instabilité de l’hétérogénéité dans le temps
Il est considéré ici qu’un patron de végétation est stable dans le temps si chaque zonage, quelque soit l’année, peut être utilisé pour représenter la variabilité spatiale d’une autre année de façon cohérente. Si deux patrons de végétations sont très différents entre une année j1 et j2, c’est-à-dire que l’hétérogénéité spatiale n’est pas stable dans le temps, le zonage de végétation sur l’année j1 représentera très mal la variabilité spatiale sur l’année j2. L’idée sous-jascente est ici de plaquer, pour chaque parcelle, l’ensemble des zonages à disposition sur chacune des données initiales de végétation (Figure 4) : une sorte de chassé-croisé qui permet de comparer deux à deux un zonage d’une année donnée aux valeurs de végétation d’une année différente. On part ici du principe que le meilleur zonage des données d’une année j est celui réalisé en utilisant justement ces données-là (Figure 4). On compare donc l’écart entre cette valeur optimale et les valeurs de réduction de variance obtenues avec des zonages d’année différentes.
Une parcelle sera donc d’autant plus stable dans le temps que l’indicateur d’instabilité sera faible.
Le deuxième indicateur d’hétérogénéité (la stabilité temporelle du patron de végétation sur une parcelle, que l’on va noter Instab_i), c’est-à-dire celui qui répond à la question : « est-ce que les patrons de végétations sont cohérent ou pas dans le temps ? », est défini comme la moyenne des écarts absolus entre l’indice de réduction de variance calculé en plaquant des zonages d’une année k sur les données de végétation d’une année différente j (j différent de k), et celui calculé en plaquant des zonages d’une année k sur les données de végétation d’une même année j (j égal à k)
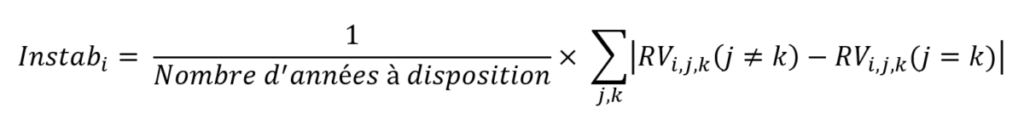
La figure 4 ci-dessous représente schématiquement comment sont calculés les indicateurs d’hétérogénéité et d’instabilité.
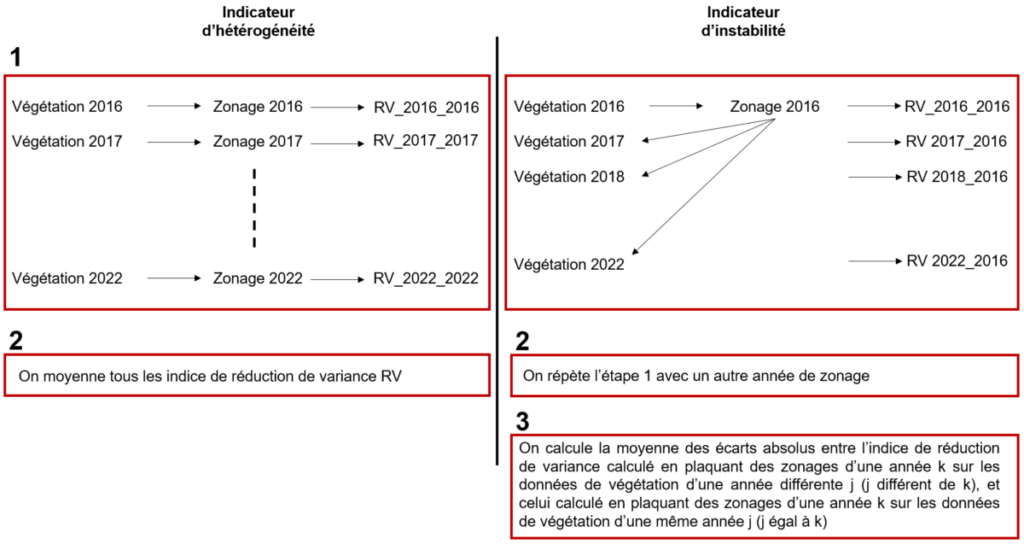
Figure 4. Etapes de calcul des indicateurs d’hétérogénéité et d’instabilité
Cartographie des indicateurs d’hétérogénéité et d’instabilité de végétation
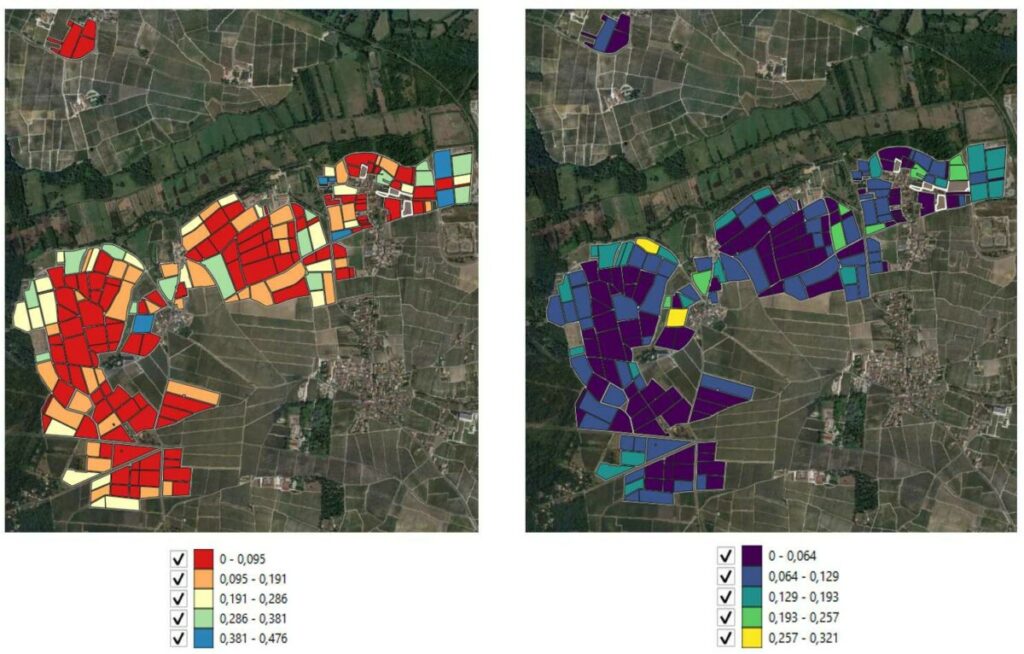
Voilà ce que donnent les résultats du calcul de ces deux indicateurs sur le site 2 (Figure 5). Je rappelle ici que ces indicateurs synthétisent l’information contenue dans de larges historiques de végétation et que leur intérêt principal réside dans leur capacité à prendre du recul sur l’état de la végétation sur le domaine.
Figure 5. Cartographie des indicateurs d’hétérogénéité de végétation (à gauche) et d’instabilité de l’hétérogénéité (à droite)
Ces indicateurs sont à utiliser en relatif. Ils permettent de hiérarchiser les parcelles les unes par rapport aux autres mais pas de fixer des seuils d’hétérogénéité et/ou d’instabilité temporelle de végétation. Ces seuils, s’ils doivent être fixés, le seront par les responsables du vignoble en utilisant leur expertise du domaine et leur représentation propre de ce qu’est un niveau d’hétérogénéité suffisant. Les seuils pourront alors potentiellement être réappliqués dans d’autres conditions opérationnelles.
L’explication de l’état de la végétation peut se faire à plusieurs niveaux :
- Au niveau du parcellaire complet (on pourrait parler d’échelle globale) : on cherchera alors plutôt à expliquer ce que l’on voit en terme de niveau d’hétérogénéité global ou de niveau de végétation global par le millésime
- Au niveau de la parcelle : si la localisation de l’hétérogénéité de végétation change sur le parcellaire, on cherchera à comprendre pourquoi avec des orientations plutôt agronomiques (sol, réserve utile…) mais aussi logistiques (parcelles avec drains cassées, parcelles récemment arrachées…)
- Au niveau de la zone : si les zones sont instables dans le temps, il serait certainement intéressant d’aller chercher une explication dans les itinéraires culturaux mis en place (fertilisation, enherbement). Dans ce premier cas, on préfèrera plutôt une gestion court terme de la modulation ou peut-être même de ne pas considérer de modulation du tout parce que le risque de se tromper est trop important. Si au contraire les zones de végétation sont stables dans le temps, l’intérêt de comparer avec l’itinéraire cultural est assez réduit. Dans ce deuxième cas, il pourra être plutôt intéressant de travailler sur de l’intra-parcellaire et de mettre en place des pratiques de modulation parce que l’on pourra raisonner sur du relativement long-terme.
Les zonages qui sont présentés dans ce dossier sont purement statistiques. Ils n’intègrent pas réellement d’expertise métier et sont basés uniquement sur les données de végétation harmonisées à disposition. Un travail a été engagé pour justement intégrer l’expertise métier et historique du personnel du domaine dans ces travaux de zonage avec notamment :
- Le ré-affinage manuel des zonages sur le terrain après visite des parcelles. Ce ré-affinage fait appel à l’expérience et la représentation que le personnel du domaine a de ses parcelles. On pourra reprocher que cette représentation soit très certainement plus large que la seule végétation et qu’elle intègre en réalité plusieurs dimensions. Mais est-ce finalement si grave que ça ?
- La classification experte des zones de végétation en niveau d’appréciation visuelle sur le terrain (Figure 6). Il faut ici comprendre qu’il était demandé aux opérateurs sur le terrain de noter un niveau de vigueur de 1 à 3 dans chaque zone dessinée, de manière à pouvoir comparer les valeurs des données de végétation dans chaque zone aux classes de végétation expertes fixées par le personnel du domaine (la classification proposée allait au départ de 1 à 5 mais cette classification trop précise n’était pas assez discriminante). L’idée étant de voir si les données de végétation dans chaque classe étaient très bien discriminées ou se chevauchaient. Cette analyse permettant dans un deuxième temps de fixer un seuil de végétation pour chacune des classes (et donc de transformer des classes statistiques de végétation en classes expertes de végétation sur le domaine), et de reprojeter ce seuil sur différentes années (en faisant attention à l’harmonisation des seuils puisque les niveaux de végétation sont sensiblement différents d’une année à l’autre).
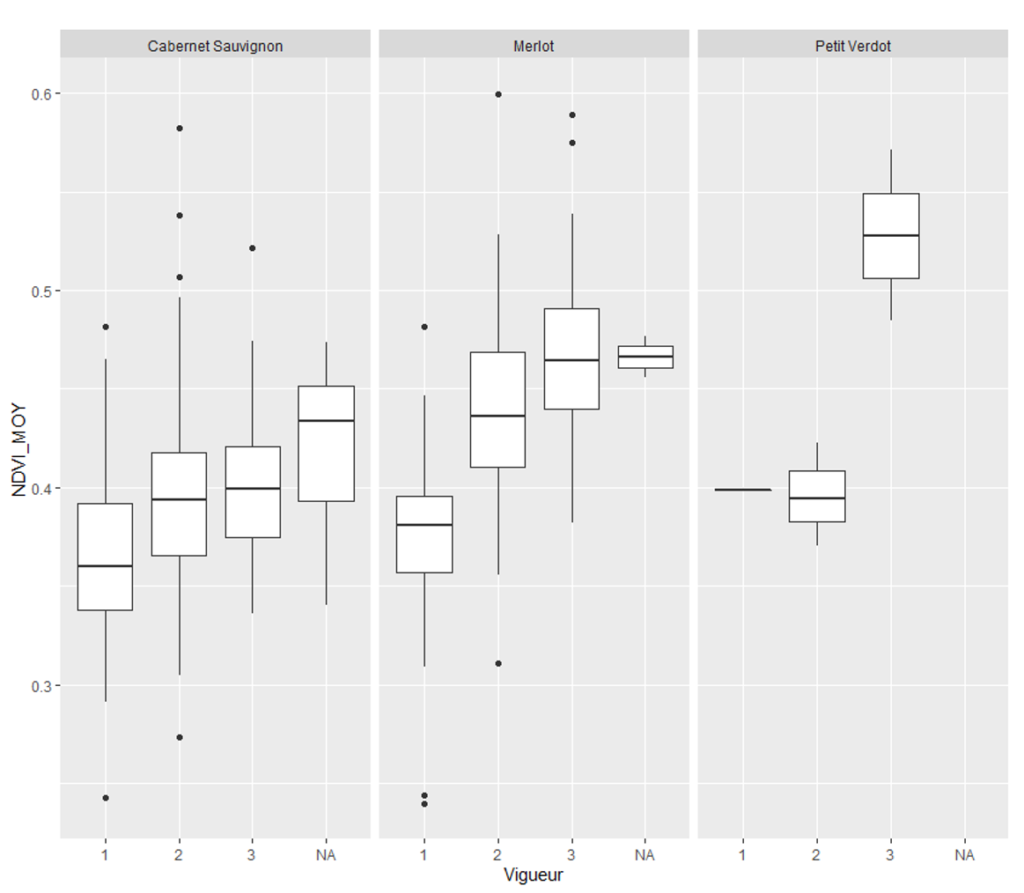
Figure 6. Adéquation entre les classes de végétation expertes (1, 2 et 3) et les données de végétation (voir tableau 1 et 2) pour les 3 cépages majoritaires du site 2.
Sur la méthodologie proposée, loin d’être parfaite, nous pouvons également identifier quelques premières limites :
- L’indice de réduction de variance dépend forcément un peu du nombre de zones dans chaque parcelle. La relation n’est toutefois pas forcément linéaire. Comme le nombre de zones n’est pas identique dans chacune des parcelles, un biais reste nécessairement un peu présent
- Nous avons donné le même poids ou la même influence à chacune des années à disposition. C’est un choix que nous avons fait, mais nous aurions pu également donner plus d’influence à certaines années plutôt que d’autres (les plus récentes par exemple).
- L’indicateur d’instabilité de zonage s’intéresse à la forme des zones, c’est-à-dire qu’il regarde si les zones restent à peu près les mêmes au cours du temps. Il faut garder en tête que cet indicateur ne donne pas d’informations sur le fait que la végétation dans ces zones puissent varier fortement. On peut par exemple imaginer des effets flip-flop avec des zones à fortes végétation une année qui deviennent des zones à faible végétation sur une année suivante, par exemple à cause de l’effet d’une pluviométrie intense sur une zone de sol particulière.
- Sans grande surprise, les résultats présentés ici dépendent de l’ensemble des méthodes de traitement de données appliquées, particulièrement le zonage et la classification des données de vigueur initiales en 6 classes à intervalles égaux.
Le travail avec le domaine viticole a également donné lieu à l’analyse de données complémentaires à la végétation, notamment sur le sol via des données de conductivité (pour le site 1) et sur le climat avec des représentations assez grossières des différentes années climatiques (proposées par les responsables du domaine). L’enjeu étant toujours de chercher à expliquer les variabilités observées de végétation. Les travaux autour du climat n’ont pas été concluants car relativement superficiels. Le gel de 2017 a potentiellement rebattu les cartes de végétation. L’année 2018, très pluvieuse, a potentiellement pu creuser les niveaux d’hétérogénéité. Les différentes acquisitions de données (par exemple les 3 périodes différentes pour le site 1) ont peut-être masqué certaines variations de végétation. Rajoutons également que la majorité des périodes phénologiques clés de la vigne ont lieu après la période d’acquisition des données.
En guise de conclusion
Les outils numériques ont cet intérêt de pouvoir aider à mesurer objectivement certains paramètres phénotypiques de la végétation (NDVI, EVI…) avec les limites que l’on y connait (corrélation plutôt que causalité, difficulté à relier à un réel état physiologique de la plante, utilisation de ces indices pour une prise de décision). Mais leur utilisation dans un contexte opérationnel reste encore très largement une affaire de spécialistes, et les contraintes techniques et logistiques ne manquent pas (changement de prestataire, analyse de données changeante au cours du temps…).
Le travail de nettoyage et de mise en forme des données est un travail à part-entière qui est déjà très utile en soi dans un contexte opérationnel puisqu’il permet déjà et surtout de partir sur de bonnes bases. Les travaux ont permis au personnel du domaine d’avoir des données de végétation harmonisées et bien recontextualisées.
Au vu des échanges récurrents avec le personnel du domaine, il apparait nécessaire que de nouvelles compétences, notamment en géomatique et en manipulation de donnée spatiales, soient internalisées dans ces structures opérationnelles. Ces compétences sont importantes pour comprendre les enjeux et limites de l’acquisition de données, avoir la main sur les processus d’acquisition et/ou de traitement de données, et surtout pour être en capacité de réagir lorsqu’un prestataire change ou qu’un traitement doive être mis à jour.
Les données historiques spatio-temporelles – comme celles de végétation que nous avons vues ici – doivent être simplifiées si elles veulent, un jour, pouvoir être utilisées sur le terrain. Autrement, nous courrons le risque de nous satisfaire de collecter des données à haute résolution qui resteront soigneusement rangées dans un tiroir.
Bibliographie
Bobryk et al., (2016). Validating a Digital Soil Map with Corn Yield Data for Precision Agriculture Decision Support. Agronomy Journal : https://acsess.onlinelibrary.wiley.com/doi/full/10.2134/agronj2015.0381
Leroux, C., Jones, H., Clenet, A., & Tisseyre, B. (2017). A new approach for zoning irregularly-spaced, within-field data. Computers and Electronics in Agriculture, 141 (C), 196-206. DOI: https://doi.org/10.1016/j.compag.2017.07.025
Leroux, C., & Tisseyre, B. (2018a). How to measure and report within-field variability – A review of common indicators and their sensitivity. Precision Agriculture. https://doi.org/10.1007/s11119-018-9598-x
Leroux, C., Jones, H., Taylor, J, Clenet, A., & Tisseyre, B. (2018b). A zone-based approach for processing and interpreting variability in multitemporal yield data sets. Computers and Electronics in Agriculture, 148, 299-308. https://doi.org/10.1016/j.compag.2018.03.029
Soutenez Agriculture et numérique – Blog Aspexit sur Tipeee