
Une parcelle agricole parfaitement homogène, ça n’existe pas ! Et c’est tout simplement dû au fait que l’on travaille avec du vivant et que l’on fait face à des phénomènes tous plus complexes les uns que les autres (sol, climat, plante, pratiques agricoles…), et qui en plus ont la fâcheuse tendance d’interagir entre eux. Ces phénomènes varient à la fois dans l’espace (et à différentes échelles – parcelle, exploitation, bassin de production…) mais aussi de temps (journée, semaine, mois…). On peut effectivement imaginer des zones de sol très différentes au sein d’une même parcelle agricole, ou une biomasse qui évolue fortement au cours de la saison. Se posent alors souvent beaucoup de questions au niveau de la variabilité ou de l’hétérogénéité de ces phénomènes ! Suis-je capable d’appréhender cette variabilité ? Suis-je capable de la prendre en compte dans mes choix tactiques et stratégiques, à court, moyen, ou long terme ? Considérer cette variabilité a-t-elle du sens au vu de mes contraintes et objectifs de production ? Mais avant tout et surtout, comment mesurer objectivement cette variabilité ?
Ce petit post fait la synthèse d’un travail réalisé pendant ma thèse : « How to measure and report within-field variability – a review of common indicators and their sensitivity » publié dans la revue Precision Agriculture. Nous nous concentrerons ici sur les indicateurs existants pour mesurer et quantifier une hétérogénéité spatiale (nous n’aborderons pas le cas du temporel ici). Les lecteurs intéressés pourront retourner lire l’intégralité de l’article.
Pourquoi utiliser des indicateurs de variabilité spatiale
Dans la littérature, on pourra distinguer quatre grands cas d’usage pour lesquels les auteurs utilisent des indicateurs de variabilité spatiale :
- Cas d’étude 1 (UC1) : Pour évaluer de manière objective l’amplitude de variation d’un phénomène. On notera ici qu’on ne parle pas de variabilité spatiale mais bien de variabilité attributaire (sans considération du spatial)
- Cas d’étude 2 (UC2) : Pour évaluer de manière objective la variabilité spatiale d’un phénomène
- Cas d’étude 3 (UC3) : Pour comparer la structure spatiale entre plusieurs attributs agronomiques dans la même parcelle, ou entre le même attribut agronomique mais entre différentes parcelles. C’est une sorte de benchmark de variabilité spatiale. Ce peut-être pour ordonner des parcelles ou des unités spatiales de la plus grande à la plus faible variabilité spatiale, ou par exemple pour comparer les impacts de certaines pratiques agricoles sur la variabilité spatiale observée.
- Cas d’étude 4 (UC4) : Pour créer une carte de modulation et évaluer si la structure spatiale peut être prise en compte (par un opérateur, machine…).
A la lecture de cette littérature, nous avons fait un certain nombre de constats, lesquels ont bien évidemment orienté notre travail. Tout d’abord, l’étude de la variabilité spatiale a été consacrée à de nombreux paramètres agronomiques différents, à la fois sur des paramètres physico-chimiques du sol, des facteurs de production sur le végétal, l’état hydrique de la plante ou encore la qualité des fruits. Ce premier constat met en avant la nécessité de disposer d’indicateurs de variabilité spatiale aussi généraux et universels que possible pour pouvoir analyser la structure spatiale de tous ces paramètres agronomiques. Deuxièmement, à l’exception du premier cas d’étude, les auteurs utilisent des mesures très différentes pour caractériser la variabilité spatiale au sein de leurs parcelles, même pour des cas d’utilisation similaires. Par ailleurs, il est intéressant de noter que, dans la littérature, le choix de ces indicateurs est mal expliqué. Cette diversité de métriques soulève nécessairement des questions sur leur sélection et leur utilisation par les praticiens : Est-ce que c’est parce qu’il n’existe pas d’indicateurs suffisamment généraux ou parce que les auteurs n’en ont pas connaissance ? Les indicateurs existants sont-ils bien adaptés à tous les cas d’utilisation possibles ? Le choix des indicateurs faits par les praticiens pourrait-il être lié à la nature des données susceptibles de changer d’une étude à l’autre ? La nature des données empêche-t-elle ou favorise-t-elle l’utilisation d’indicateurs spatiaux spécifiques ? D’un point de vue général, les indicateurs de variabilité spatiale sont-ils facilement disponibles et utilisables par les utilisateurs ?
Quels sont les principaux indices de la littérature
Nous avons classé les indicateurs de variabilité spatiale en 4 grandes catégories (décidément, c’est un chiffre qui commence à revenir souvent). Je vous laisse aller lire l’article pour voir les formules pour calculer ces indicateurs :
- Les indicateurs basés sur la distribution générale des données (distribution-based metrics) : On retrouve notamment ici l’assez classique « Coefficient de Variation» largement rapporté par la communauté. C’est un indicateur très simple à calculer qui permet de mesurer l’amplitude de variation d’un phénomène. Comme l’écart-type des données est pondéré par la moyenne de ces mêmes données, il a l’avantage de pouvoir être comparé assez facilement entre différents jeux de données. Ca reste néanmoins un indicateur basé sur la distribution des données, qui ne prend pas en compte l’aspect spatial des données comme le montre la figure ci-dessous.

Figure 1. De gauche à droite, la parcelle est de plus en plus structurée mais le coefficient de variation est le même.
- Les indicateurs géostatistiques (« geostatistical-based metrics ») : Ce sont les indicateurs qui sont calculés après avoir construit un semi variogramme expérimental et y avoir ajusté un modèle théorique de variogramme (je vous invite à relire des posts précédents sur la variographie si ce n’est plus très clair). Ce sont les paramètres de ce modèle théorique de variogramme (portée, pallier, et effet pépite) qui sont principalement utilisés pour calculer des indicateurs comme celui de Cambardella, le MCD, ou encore l’indice d’opportunité Oi [même si ce dernier reste quand même un peu plus compliqué à calculer).
- Les indicateurs basés sur une empreinte spatiale machine (« machine footprint-based metrics). Pour ces indicateurs, on simule le passage d’une machine qui va réaliser une application donnée, et on évalue si la machine sera capable de prendre en compte ou non la variabilité spatiale dans les données. On retrouvera dans cette catégorie l’indice d’opportunité technique TOi, et sa déclinaison floue, le FTOi, qui reprend les mêmes concepts que le TOi, en y ajoutant des composantes de logique floue (incertitude du positionnement machine à chaque instant, incertitude sur la mesure des données…).
- Les indicateurs basés sur un zonage pré-éxistant (« zoning-based metrics »). On retrouve ici des indicateurs qui vont comparer l’intérêt d’un zonage donné sur la parcelle par rapport à une gestion uniforme de cette même parcelle. Il faut donc avoir déjà établi un zonage du paramètre agronomique d’intérêt, c’est-à-dire avoir déjà imaginé une application différentiée sur la parcelle. On retrouve ici l’indicateur d’opportunité de zonage (ZOI) qui simule le passage d’une machine sur la parcelle zonée pour évaluer si la machine est capable de prendre en compte le zonage délimité (en considérant la taille de la machine, sa capacité à passer d’un traitement A à un traitement B etc…). Un deuxième indicateur qui n’a pas été cité dans l’article mais qui peut se trouver intéressant aussi, est celui dit de Réduction de Variance (RV), qui évalue à quel point la variance est réduite dans chacune des zones délimitées par rapport à la variance initiale dans la parcelle. Cet indicateur ne prend par contre pas en compte le fait qu’une machine puisse passer dans la parcelle (avec ses contraintes de taille, de latence etc…). L’indice RV est présenté dans l’article « Validating a Digital Soil Map with Corn Yield Data for Precision Agriculture Decision Support » publié dans la revue Agronomy Journal.
A quoi faire attention avant d’utiliser les indices
De la diversité des jeux de données d’entrée
Il faut bien avoir à l’esprit que tous les jeux de données collectés sont différents les uns des autres. Ca peut paraitre bête à dire, mais le traitement qui sera fait sur les données doit être complètement réfléchi en fonction de la nature et des caractéristiques propres des données et de la façon dont elles ont été acquises ; et c’est tout à fait le cas lorsque l’on veut calculer un indicateur d’hétérogénéité (nous y reviendrons dans la section suivante).
Le choix d’une méthode et d’un vecteur d’acquisition de données est en général totalement justifié ! Ce choix peut être contraint par une spécificité agronomique (ex : l’architecture palissée d’un vignoble), le coût d’acquisition de la donnée, le temps passé sur le terrain, ou encore les compétences ou expertise requise pour mesurer le plus finement possible le paramètre agronomique d’intérêt. En fonction de ces choix, les données auront par exemple une résolution spatiale plus ou moins forte (c’est la densité des observations), et ces données pourront être régulièrement ou irrégulièrement réparties dans l’espace.
Les données collectées ont elle aussi des caractéristiques propres en fonction du support de la mesure (sol, plante…). Certaines données seront par exemple plus ou moins auto corrélées et structurées dans l’espace [c’est d’ailleurs ce que l’on cherche à mesurer avec un indicateur de variabilité spatiale]. Certains jeux de données pourront être considérés comme stationnaires dans l’espace, d’autres non. Pour rappel, l’hypothèse de stationnarité, c’est le fait que des métriques comme la moyenne ou la variance soient admis comme stables sur n’importe quel espace considéré – on rappellera ici que c’est une des hypothèses fortes pour la modélisation des variogrammes (je vous invite à relire un ancien article de blog sur la variographie pour vous rafraichir la mémoire).
Dans l’article que nous avons rédigé, ce sont ces quatre caractéristiques que nous avons contrôlées sur des jeux de données simulés, pour en étudier leur impact sur les indicateurs d’hétérogénéité communément utilisés dans la littérature.
Les caractéristiques des indicateurs de variabilité spatiale
Ce dont on se rend compte, sans rentrer dans le détail (je vous invite à lire l’article complet), c’est que les 4 critères que nous avons fait varier ont un impact sur la valeur des indicateurs de variabilité spatiale. Alors vous pourrez me dire que c’est plutôt rassurant quand il s’agit du niveau d’autocorrélation ou de structure spatiale parce que ça veut dire que les indicateurs sont capables de discriminer des jeux de données avec des niveaux de variabilités spatiales différentes. Et je vous répondrai que c’est effectivement le cas même si tous les indicateurs n’ont pas la même sensibilité à ces différents niveaux de variabilité spatiale. Ce n’est pas forcément très grave tant qu’on le sait après tout !

Figure 2. Sensibilité des indicateurs de variabilité spatiale à l’autocorrélation dans les données. Les données simulées S1, S2 et S3 font respectivement référence à une structure spatiale faible, moyenne, et forte. Les lettres A à J représentent des caractéristiques d’empreinte machine.
Par contre, là où il faut commencer à faire attention, c’est quand on fait varier la densité des observations disponibles, la régularité des observations ou encore l’hypothèse de stationnarité du phénomène étudié. Et on se rend compte que ces impacts sont loin d’être négligeables ! C’est-à-dire qu’utiliser le même indicateur d’hétérogénéité pour comparer des jeux de données aux caractéristiques différentes peut parfois conduire à des conclusions très loin de la réalité. On se rend par exemple compte que :
- Plus la densité d’observations est faible, moins on peut calculer les indicateurs géostatistiques, et plus des indicateurs tels le TOi ou le ZOi donnent la fausse impression que la parcelle est très bien structurée (contrairement au FTOi qui gère assez bien le manque de données)
- On ne peut pas calculer d’indicateurs géostatistiques sur les données non stationnaires (ça on le savait quand même déjà)
- Avoir des données régulièrement ou irrégulièrement réparties dans l’espace n’impactent pas trop les indicateurs géostatistiques et ceux basés sur une empreinte machine.

Figure 3. Sensibilité des indicateurs de variabilité spatiale à la régularité des données. Les lettres A à J représentent des caractéristiques d’empreinte machine.

Figure 4. Sensibilité des indicateurs de variabilité spatiale à la densité des observations. v

Figure 5. Sensibilité des indicateurs de variabilité spatiale à la stationnarité des données. Les lettres A à J représentent des caractéristiques d’empreinte machine.
Les caractéristiques des données collectées sont une des facettes qu’il est important de prendre en compte, mais ce n’est pas la seule. D’un point de vue très pratico-pratique, il faut penser à l’utilisateur qui veut quantifier le niveau d’hétérogénéité dans ses données. Le choix de l’indicateur qu’il va utiliser va dépendre d’aspects aussi concrets que l’accessibilité de ces indicateurs sur un outil existant ou sur la facilité d’implémentation de ces indices. On peut tout à fait comprendre que si un indicateur est complexe à calculer et qu’en plus de ça, il n’est disponible sur aucun outil SIG classiquement utilisé, l’utilisateur – malgré toute sa bonne volonté – ne pourra pas le considérer. A côté de ça, le niveau d’expertise de l’utilisateur sur la compréhension des indicateurs doit rentrer en ligne de compte. Certains indicateurs sont par exemple assez sensibles à la paramétrisation réalisée par l’utilisateur. De la même façon qu’avec les 4 critères principalement testés, si l’utilisateur ne comprend pas clairement ce qu’il fait, les conclusions s’en trouveront encore une fois erronées. L’exemple le plus parlant concerne l’ajustement d’un modèle théorique de variogramme aux données. En fonction de la façon dont le modèle est ajusté, les indicateurs géostatistiques peuvent être très différents !
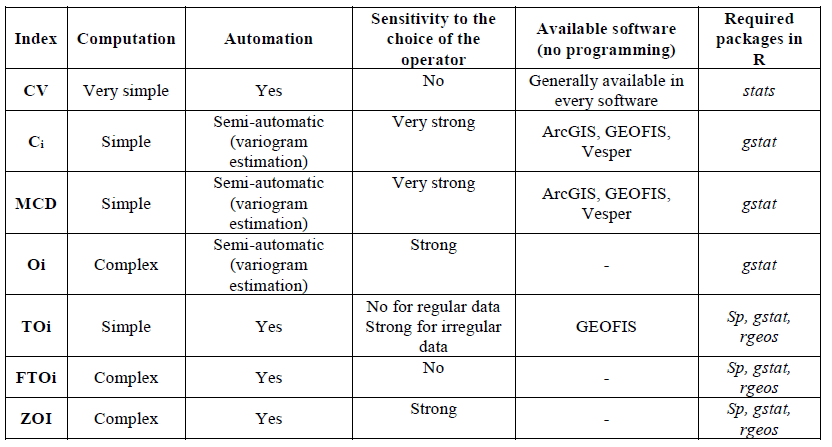
Figure 6. Calcul et accessibilité des différents indicateurs de variabilité spatiale
Vers une utilisation conjointe et réfléchie des indices
A la fin de ce travail de veille et de benchmark d’indicateurs de variabilité spatiale, nous nous sommes rendus compte que le choix d’un indicateur de variabilité spatiale était loin d’être évident et qu’il manquait un arbre de décision pour s’orienter et se retrouver dans cette complexité. Et c’est ce que nous avons produit dans la dernière figure de ce post. Choisir un indicateur de variabilité adapté est certes intéressant pour ne pas faire dire n’importe quoi à ses données, mais il l’est tout aussi pour pouvoir plus facilement comparer des expérimentations ou résultats les uns aux autres. Comparer des indicateurs de variabilité différents n’a pas vraiment de sens en soi dans la mesure où ils ont chacun leur sensibilité aux données. Peut-être ce travail poussera-t-il les acteurs à standardiser leurs mesures de variabilité pour y voir plus clair ? Peut-être manque-t-il un indicateur plus générique et standard pour mesurer cette variabilité spatiale ?
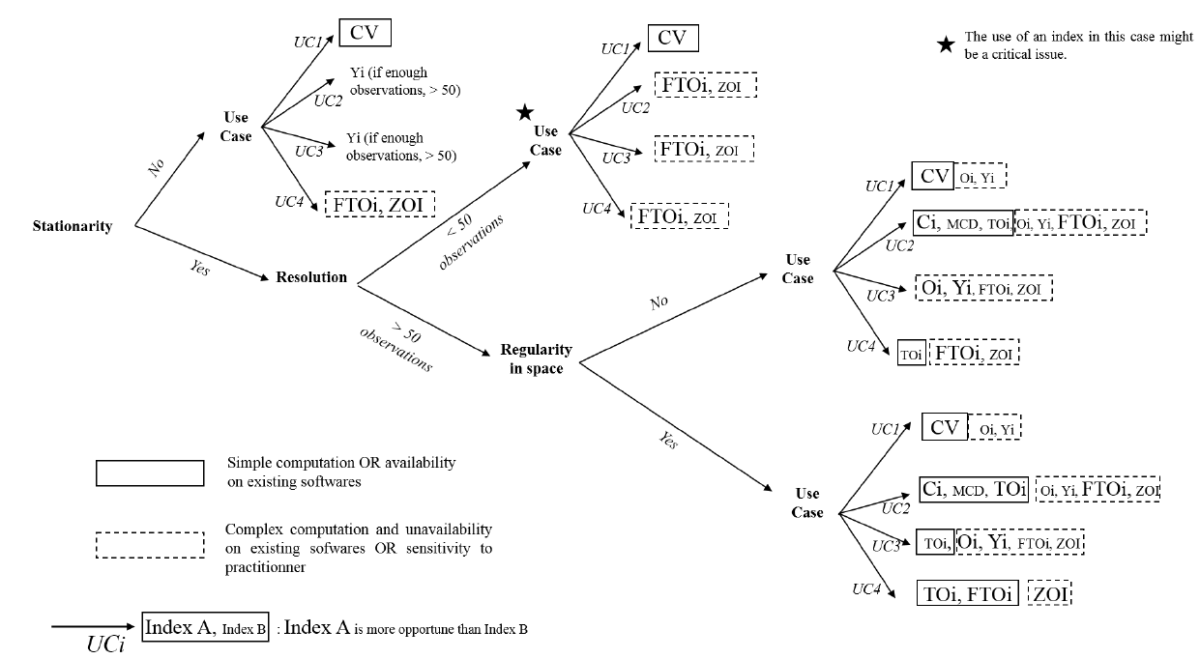
Figure 7. Arbre de décision pour orienter le choix vers un indicateur de variabilité spatiale
Soutenez les articles de blog d’Aspexit sur TIPEEE
Un p’tit don pour continuer à proposer du contenu de qualité et à toujours partager et vulgariser les connaissances =) ?