
Les campagnes de terrain sont un élément fondamental à la plupart des études en agriculture de précision. L’échantillonnage est nécessaire pour étalonner un modèle agronomique ou pour évaluer la structure spatiale d’une variable d’intérêt par proxy ou télédétection (teneur en eau ou en nutriments du sol). La position dans l’espace des échantillons doit être réfléchie sérieusement dans le sens où les campagnes de terrain sont souvent fastidieuses, chronophages, et coûteuses. Il faut s’assurer également que les échantillons collectés permettront de caractériser l’ensemble de la structure spatiale sur une parcelle. Il y a donc un compromis à faire entre sur-échantillonner (cher et pénible) et sous échantillonner (peu cher mais les parcelles sont mal caractérisées). Comme le nom le laisse à penser, l’échantillonnage orienté est une stratégie dont l’objectif est de positionner précisément les échantillons dans les parcelles pour optimiser la caractérisation des parcelles et les contraintes de la campagne de terrain. Plusieurs approches d’échantillonnage existent et ces dernières sont détaillées dans ce post.
Echantillonnage aléatoire
L’échantillonnage aléatoire ne peut pas être inclus dans les méthodes d’échantillonnage orienté. Néanmoins, c’est la méthode la plus simple à laquelle on peut penser. Les échantillons sont simplement positionnés dans la parcelle de manière totalement aléatoire. Intuitivement, il y a une forte probabilité que toute l’information de la parcelle ne soit pas récupérée. Il est assez clair que cette méthode d’échantillonnage n’est pas vraiment efficace
Echantillonnage régulier ou basé sur une grille
L’échantillonnage régulier est une méthode relativement simple. Cette méthode part du principe qu’une manière fiable de capturer la structure spatiale sur toute une parcelle est de positionner des échantillons régulièrement espacés sur toute la parcelle de telle sorte que toute la parcelle soit recouverte d’échantillons. D’une certaine façon, cette méthode n’est pas vraiment si orientée sur cela parce qu’elle n’est pas particulièrement réfléchie. L’objectif est plutôt d’être exhaustif en récupérant un grand nombre d’échantillons sur toute la parcelle. Cette méthode a l’avantage d’être relativement facile à mettre en place mais elle ne prend en compte aucune information auxiliaire dans le champ. Avec un échantillonnage régulier, on pourrait manquer soit un phénomène très spécifique ou, au contraire, récupérer de l’information répétitive aux dépens de temps et d’argent.
Echantillonnage irrégulier
L’échantillonnage régulier est intéressant à considérer dans le sens où il est relativement simple à mettre en place et que l’ensemble de la parcelle est généralement parcouru. Néanmoins, lorsque l’on cherche à évaluer précisément la structure spatiale d’une propriété agronomique d’intérêt, ce type de schéma d’échantillonnage apparaît un peu limité. Avec un échantillonnage régulier, relativement peu d’importance est accordée à la corrélation entre des observations séparées par des courtes distances (parce que l’on préfère échantillonner partout dans la parcelle, quitte à échantillonner moins en chaque endroit de la parcelle). Cet aspect est problématique pour la construction du variogramme expérimental parce que l’effet pépite est souvent mal estimé et donc le modèle ajusté au variogramme expérimental n’est pas optimal. Dans ces cas précis, des échantillonnages irréguliers sont plutôt préconisés parce qu’ils sont faits pour optimiser l’évaluation de la structure spatiale à plusieurs échelles. Un exemple est proposé en Figure 1 mais beaucoup d’autres schémas d’échantillonnage sont possibles
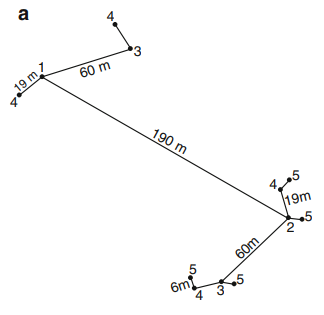
Figure 1. Exemple de schéma d’échantillonnage irrégulier
Echantillonnage stratifié (utilisation d’informations auxiliaires)
Lorsqu’une variable ou une information auxiliaire (en général avec une haute résolution spatiale) est disponible pour orienter ou aider l’échantillonnage, on parle d’échantillonnage stratifié.
Par exemple, avant de réaliser des analyses de sol complexes sur toute la parcelle, il pourrait être intéressant de positionner les échantillons dans la parcelle en fonction d’une information de conductivité electrique apparente du sol ou d’une carte de biomasse de végétation.
Dans ce cas, l’information auxiliaire peut être par exemple classifiée en quantiles ou par un algorithme de partitionnement classique comme le k-means (ou tout autre méthode de classification). L’information auxiliaire peut être aussi divisée en zones de modulation. Dans ce dernier cas, les échantillons sont alors placés au sein de chaque zone et le nombre d’échantillons par zone peut dépendre de variabilité ou de la taille de chaque zone (on parle plutôt d’échantillonnage par zone ici, Figure 2). Il faut noter que cette information auxiliaire utile peut être univariée ou multivariée. En effet, la classification ou le découpage en zones peut impliquer plus d’une variable à la fois
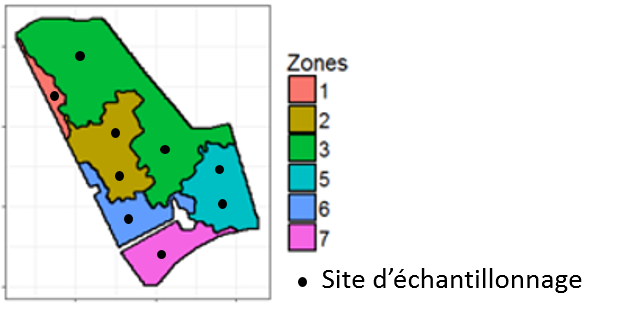
Figure 2. Exemple d’échantillonnage orienté par zone
Echantillonnage avec un variogramme
Comme il l’a été dit dans un post précédent, le variogramme peut être utilisé pour aider à définir la distance d’échantillonnage entre les observations. Pour ce faire, des données auxiliaires doivent être aussi disponibles comme dans le cas de l’échantillonnage stratifié. La règle d’or qui est recommandée est de considérer la distance optimale d’échantillonnage comme la moitié de la portée pratique du variogramme correspondant à la variable auxiliaire.
Echantillonnage avec une base de données historique
La dernière méthode présentée met en avant l’utilisation d’une base de données historique. L’objectif est de mettre à profit des échantillons collectés sur plusieurs années sur des sites précis pour sélectionner les sites qui sont les plus pertinents pour caractériser une variable d’intérêt. Ces variables d’intérêt sont toujours relativement difficiles et fastidieuse à obtenir.
Par exemple, imaginez que vous vouliez suivre l’état hydrique des plantes au sein d’une parcelle mais que vous ne sachiez pas exactement où positionner vos échantillons. Une possibilité pourrait être de réaliser un échantillonnage régulier sur les mêmes sites pendant plusieurs années avec une bombe à pression de Scholander (par exemple entre trois et cinq ans). Ensuite, un modèle de corrélation pourrait être construit entre les sites pour déterminer l’état hydrique des plantes sur l’ensemble des sites à partir de seulement quelques sites de référence. Imaginons que 40 sites aient été sélectionnés au départ. Le modèle serait par exemple capable de déduire l’état hydrique des plantes sur ces 40 sites en utilisant seulement la mesure de l’état hydrique sur 6 de ces sites. Dans ce cas, ces 6 sites pourraient être utilisés dans les années suivantes comme des sites de références pour expliquer précisément l’état hydrique des plantes sur l’ensemble de la parcelle.
Bien évidemment, cette méthode demande un effort important au début de l’analyse pour calibrer le modèle de prédiction. Par contre, une fois que ce modèle est établi et bien calibré, le suivi de la variable d’intérêt est largement simplifié.
Soutenez les articles de blog d’Aspexit sur TIPEEE
Un p’tit don pour continuer à proposer du contenu de qualité et à toujours partager et vulgariser les connaissances =) ?